一、基础数据类型
List、Tuple、Dict、Set四种数据类型
1. List 和 Tuple
- List 是一种可变的有序表,可以随时添加和删除其中的元素
- Tuple 是一种不可变的有序序列,不能对其进行修改
2. Dict 和 Set
- Dict 是一种映射类型,key-value 对的集合
- Set 是一种无序不重复元素的集合
3. 定义可变参数和默认参数
写函数定义可变参数时,在参数前加``,参数本身就从 list 变成了 tuple
定义默认参数需要指向不变对象:
pythonCopy codedef func(L = None): if L is None: L = []nums表示把nums这个 list 的所有元素作为可变参数传进去。这种写法相当有用,而且很常见。
4 arguments
可变参数和关键字参数
- 对于位置参数,想要参数可变,最早想到传入一个 list 或者 tuple。如果使用可变参数的话:
- 可变参数(
args)允许你传入0个或任意个参数,这些可变参数在函数调用时自动组装为一个 tuple。 - 而关键字参数(
*kw)允许你传入0个或任意个含参数名的参数,这些关键字参数在函数内部自动组装为一个 dict。
- 可变参数(
尾递归优化
- 尾递归调用时,如果做了优化,栈不会增长,因此,无论多少次调用也不会导致栈溢出。
- 遗憾的是,大多数编程语言没有针对尾递归做优化,Python 解释器也没有做优化,所以,即使把 fact(n) 函数改成尾递归方式,也会导致栈溢出。
Slice 和迭代
Slice
列表名[start : stop : step]
取前10个数:
[:10]或者[0:10]左闭右开
取11到20:
[10:20]取后10个数:
[-10:]所有数字,隔五个取一个:
[::5]
List、Tuple、String 都可以使用 slice。
使用切片和递归移除空白字符
pythonCopy codedef trim(s):
if s[:1] == ' ':
return trim(s[1:])
elif s[-1:] == ' ':
return trim(s[:-1])
else:
return s
列表生成式
基本用法
理论上生成{1x1,2x2,3x3,…,10x10}可以利用循环:
L = []
for x in range(1, 11):
L.append(x * x)
print(L)
但是如果使用列表生成式:
[x * x for x in range(1, 11)]
添加条件筛选
可以在列表生成式中加上 if 来筛选:
[x * x for x in range(1, 11) if x % 2 == 0]
嵌套循环
可以使用双循环生成全排列:
[m + n for m in 'ABC' for n in 'XYZ']
结合字符串方法
将字符串列表转换为小写:
L = ['Hello', 'World', 'IBM', 'Apple']
[s.lower() for s in L]
if-else 用法
在一个列表生成式中,for 前面的 if-else 是表达式,而 for 后面的 if 是过滤条件,不能带 else。
生成器 generator
在 Python 中,这种一边循环一边计算的机制,称为生成器(generator)。
yield 语句
注意,赋值语句:
a, b = b, a + b
相当于:
t = (b, a + b) # t是一个tuple
a = t[0]
b = t[1]
yield 与 print 不同,不会输出到屏幕。
获取返回值
但是用 for 循环调用 generator 时,拿不到 generator 的 return 语句的返回值。如果想要拿到返回值,必须捕获 StopIteration 错误,返回值包含在 StopIteration 的 value 中:
g = fib(6)
try:
x = next(g)
print('g:', x)
x = next(g)
except StopIteration as e:
print('Generator return value:', e.value)
迭代器 Iterator
可以被 next() 函数调用并不断返回下一个值的对象称为迭代器(Iterator)。
生成器都是 Iterator 对象,但 list、dict、str 虽然是可迭代的(Iterable),却不是 Iterator。
把 list、dict、str 等 Iterable 变成 Iterator 可以使用 iter() 函数:
isinstance(iter([]), Iterator) # True isinstance(iter('abc'), Iterator) # True
二、函数定义及使用
函数式编程:高阶函数 FP:Higher-order function
高阶函数Higher-order function
高阶函数的优势:
变量可以指向函数
f = abs函数名也是变量
abs = 10
编写高阶函数目的是让函数可以相互嵌套调用。
map()
比如我们有一个函数 f(x) = x^2,要把这个函数作用在一个列表 [1, 2, 3, 4, 5, 6, 7, 8, 9] 上,就可以用 map() 实现:
map(f, [1,2,3,4,5,6,7,8,9])
等价于利用循环:
L = []
for n in [1,2,3,4,5,6,7,8,9]:
L.append(f(n))
reduce()
reduce() 把一个函数作用在一个序列 [x1, x2, x3, ...] 上,这个函数必须接收两个参数,reduce() 把结果继续和序列的下一个元素做累积计算。
filter()
filter() 把传入的函数依次作用于每个元素,然后根据返回值是 True 还是 False 决定保留还是丢弃该元素。
def not_empty(s):
return s and s.strip()
list(filter(not_empty, ['A', '', 'B', None, 'C', ' ']))
# ['A', 'B', 'C']
sorted()
sorted() 可以对 list、string 等进行排序。要进行反向排序,可以传入 reverse=True 参数。
sorted(['Zoo', 'Credit', 'bob', 'about'], reverse=True)
参数key
key 参数指定排序时所用的映射函数。
L = [('Bob', 75), ('Adam', 92), ('Bart', 66), ('Lisa', 88)]
def by_name(t):
return t[0]
sorted(L, key=by_name)
# [('Adam', 92), ('Bart', 66), ('Bob', 75), ('Lisa', 88)]
返回函数
函数作为返回值
相关参数和变量都保存在返回的函数中,这种称为“闭包(Closure)”的程序结构拥有极大的威力。
闭包
返回闭包时牢记一点:返回函数不要引用任何循环变量,或者后续会发生变化的变量。
关于闭包值得一提的是:
从函数中返回函数其实并不需要在一个函数里去执行另一个函数,我们也可以将其作为输出返回出来:
def hi(name="yasoob"):
def greet():
return "now you are in the greet() function"
return greet
a = hi()
# a 现在指向了 hi() 函数中的 greet() 函数
在 if/else 语句中我们返回 greet 和 welcome,而不是 greet() 和 welcome()。因为带括号会执行函数,而没有括号可以赋值给其他变量。
括号代表函数执行,可以重复执行。
nonlocal
可以通过 nonlocal 改变全局变量。
练习:
利用闭包返回一个计数器函数,每次调用它返回递增整数:
def createCounter():
x = 0
def counter():
nonlocal x
x = x + 1
return x
return counter
装饰器Decorator
装饰器相关要注意闭包的用法。
假设我们要增强 now() 函数的功能,比如在函数调用前后自动打印日志,但又不希望修改 now() 函数的定义,这种在代码运行期间动态增加功能的方式,称之为“装饰器”(Decorator)。
基本装饰器写法
一个不带参数的装饰器写法如下:
import functools
def log(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('call %s():' % func.__name__)
return func(*args, **kw)
return wrapper
针对带参数的装饰器
如果装饰器本身需要传入参数,可以编写一个返回装饰器的高阶函数:
import functools
def log(text):
def decorator(func):
@functools.wraps(func)
def wrapper(*args, **kw):
print('%s %s():' % (text, func.__name__))
return func(*args, **kw)
return wrapper
return decorator
注意返回值
不能忘记返回函数调用的返回值,否则会导致修饰后函数失效。
# 错误示例
def metric(fn):
def wrapper(*args, **kw):
fn(*args, **kw)
# 这里应该return fn(*args, **kw)
return wrapper
装饰器的效果是你传给它一个函数,它返回一个新的函数。
偏函数 Partial Function
当函数的参数个数太多,需要简化时,可以使用 functools.partial 创建一个新的函数,这个新函数可以固定住原函数的部分参数,从而在调用时更简单。
举个例子,二进制字符串转整数的函数:
int('12345', base=2)
但是这样仍然稍显麻烦,可以使用 functools.partial 使得调用更简洁:
import functools
int2 = functools.partial(int, base=2)
int2('1000000')
通过偏函数,可以使代码更加简洁
三、面向对象编程
类和对象
面向对象编程(Object Oriented Programming, OOP)是一种程序设计思想。OOP 把对象作为程序的基本单元,一个对象包含了数据和操作数据的函数。
- 类是创建实例的模板,而实例则是具体的对象,各个实例的数据互相独立。
- 方法就是与实例绑定的函数,可以直接访问实例的数据。
- 通过在实例上调用方法,直接操作对象内部的数据,无需知道方法内部实现。
Python 允许对实例变量绑定任何数据,也就是说,两个实例变量即使是同一个类的不同实例,但拥有的变量名称也可能不同。
练习:
请把下面的 Student 类的 gender 字段对外隐藏起来:
class Student:
def __init__(self, name, gender):
self.gender = gender
# 修改如下:
class Student:
def __init__(self, name, gender):
self.__gender = gender
访问 gender 字段改为通过方法:
def get_gender(self):
return self.__gender
bart = Student('Bart', 'male')
print(bart.get_gender())
继承和多态
- 子类继承父类的所有属性和方法。
- 子类可以定义自己特有的方法,也可以对父类方法进行重写,这称为多态。
- Python 中,类可以作为数据类型传入函数,根据鸭子类型,不关心参数是什么类型,只关心参数是否有调用的属性和方法。
例如:
pythonCopy codeclass Animal:
def run(self):
print('Animal is running...')
class Dog(Animal):
def run(self):
print('Dog is running...')
def func(animal):
animal.run()
dog = Dog()
func(dog)# Dog is running...
这里 func() 函数接收一个 Animal 类型的参数。在调用时,不关心它的实际类型是 Animal 还是 Dog,只要保证传入的对象有 run() 方法即可。这就是多态的一种体现。
获取对象信息
判断类型
使用
type()获取类型:type(123) # <class 'int'> type('str') # <class 'str'>isinstance()判断类型关系:isinstance([1, 2, 3], (list, tuple)) # True
获取属性和方法
dir()可以获取对象的所有属性和方法名。getattr()、setattr()以及hasattr()可以直接操作对象属性:hasattr(obj, 'x') # 是否有属性'x' getattr(obj, 'x') # 获取属性'x' setattr(obj, 'y', 19) # 设置一个属性'y'
实例属性和类属性
- 实例属性属于各个实例所有,互不干扰。
- 不要对实例属性和类属性使用相同的名字,否则将产生难以发现的错误。
练习:
为 Student 类增加一个类属性,每创建一个实例,该属性自动增加:
class Student(object):
count = 0
def __init__(self, name):
self.name = name
Student.count += 1
# 测试:
bart = Student('Bart')
print(Student.count) # 1
lisa = Student('Lisa')
print(Student.count) # 2
为什么要使用 Student.count 而不能是 self.count?
因为 self.count 是实例属性,而 Student.count 是类属性。两者不应该使用相同的名字。
多重继承和MixIn
- 通过多重继承,一个子类可以同时获得多个父类的所有功能。
- MixIn的目的就是给一个类增加多个功能,通过多重继承来组合多个MixIn的功能,而不是设计多层次的复杂继承关系。
- MixIn 类包含其他类要用到的方法,但不必充当父类。
MixIn 的优点:
- 组合胜于继承
- 避免复杂的多继承
例如:
class RunMixin():
def run(self):
print('Running...')
class FlyMixin():
def fly(self):
print('Flying...')
class Dog(RunMixin):
pass
class Bird(FlyMixin):
pass
定制类和枚举类
定制类
可以针对不同的场景定制类:
__str__()定制打印输出__iter__()定制为可迭代对象__getitem__()定制切片__getattr__()动态返回属性__call__()定制为可调用对象
例如:
class Chain(object):
def __init__(self, path=''):
self._path = path
def __call__(self, path):
return Chain('%s/%s' % (self._path, path))
def __str__(self):
return self._path
print(Chain().users('michael').repos)
# /users/michael/repos
枚举类
枚举类可以定义常量,例如:
from enum import Enum
class Gender(Enum):
Male = 1
Female = 2
class Student(object):
def __init__(self, name, gender):
self.name = name
self.gender = gender
bart = Student('Bart', Gender.Male)
使用元类
Python 中类也是对象,类型就是 type。
使用 type 创建类
要创建一个类对象,可以使用 type() 函数:
def fn(self):
print('Hello')
Hello = type('Hello', (object,), dict(hello=fn))
type() 传入3个参数:
- 类名
- 继承的父类集合,注意 Python 支持多重继承
- 类的方法名称与函数绑定
metaclass
元类可以控制类的创建过程:
# metaclass是类的模板,所以必须从`type`类型派生:
class ListMetaclass(type):
def __new__(cls, name, bases, attrs):
attrs['add'] = lambda self, value: self.append(value)
return type.__new__(cls, name, bases, attrs)
# 指示使用ListMetaclass来定制类
class MyList(list, metaclass=ListMetaclass):
pass
L = MyList()
L.add(1)
L
# [1]
四、其他核心概念
slots
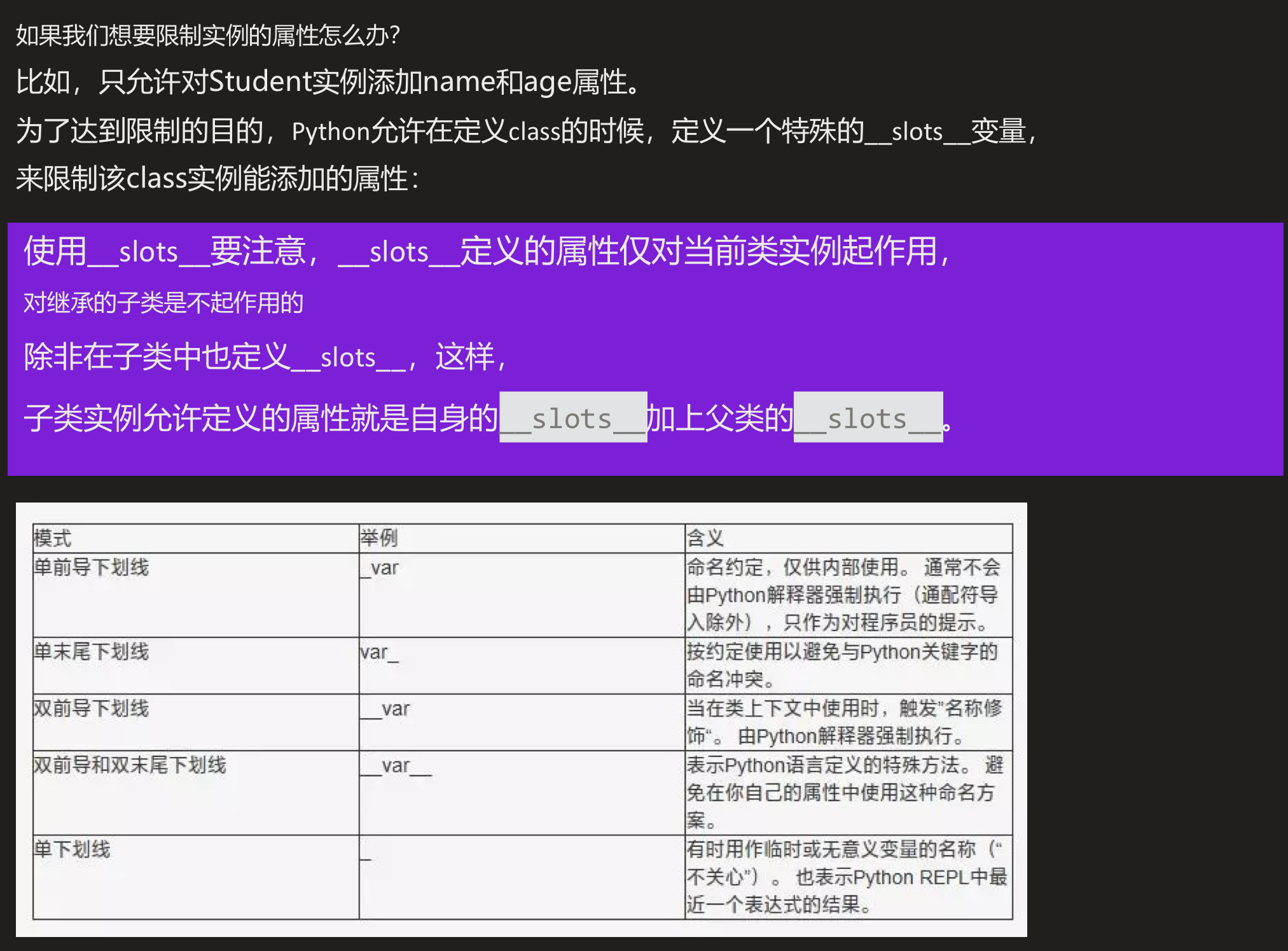
@property
@property 装饰器可以让方法像属性一样访问,既能检查参数,又可以简化代码。
注意方法名不要和实例变量同名,以免递归错误。
class Student:
def __init__(self, birth):
self._birth = birth
@property
def birth(self):
return self._birth
# 方法名和实例变量名不同,就避免了递归错误
练习:
请利用 @property 给一个 Screen 对象添加 width、height 属性,以及一个只读属性 resolution:
class Screen:
def __init__(self):
self._width = 0
self._height = 0
@property
def width(self):
return self._width
@width.setter
def width(self, value):
if not isinstance(value, int):
raise ValueError('width must be an integer!')
if value < 0:
raise ValueError('width must be positive!')
self._width = value
@property
def height(self):
return self._height
@height.setter
def height(self, value):
# 同样需要判断类型和值
...
@property
def resolution(self):
return self._width * self._height
模块 Module
使用模块的好处:
- 最大的好处是大大提高了代码的可维护性
- 使用模块还可以避免函数名和变量名冲突。相同名字的函数和变量完全可以分别存在不同的模块中。
模块作用域:
- 在一个模块中,我们可能会定义很多函数和变量,但有的我们希望被外部访问,有的希望仅在模块内部使用。
- 正常的函数和变量名是公开的(public),可以被直接引用,比如:
abc,x123,PI等。 __xxx__这样的变量是特殊变量,可以被直接引用,但是有特殊用途,比如__author__,__name__就是特殊变量。_xxx和__xxx这样的函数或变量就是非公开的(private),不应该被直接引用。__name__变量取值为模块名字,当模块被直接执行时值为'__main__'。
错误处理和调试
错误处理
- 测试数据出错时,可以用
print()打印错误信息,或者使用assert进行断言。 assert后面表达式若为 False 将抛出AssertionError。
调试
使用
print()打印变量信息,可以查看程序执行过程。使用 debugger 调试,如 pdb:
import pdb pdb.set_trace()程序运行会自动在此处停住,可以查看当前堆栈变量信息,或者逐行执行代码。
IDE也提供GUI调试,如设置断点,查看变量信息等。
标准库 logging 模块可以进行日志记录,设置日志级别、日志文件保存等,方便追踪问题。
序列化
序列化就是将对象转换为可存储或传输的格式,在Python中可以使用pickle模块。
pickle 序列化
import pickle
data = {...} # 对象
b = pickle.dumps(data) # 序列化为bytes
f = open('data.pkl', 'wb')
pickle.dump(data, f) # 写入文件
f.close()
f = open('data.pkl', 'rb')
d = pickle.load(f) # 从文件读取
f.close()
pickle可以序列化大多数Python对象,但有些类型可能需要 handling 模块支持。
JSON 序列化
JSON是一种通用的数据格式,也可以用于序列化。
import json
json.dumps(data) # 序列化为JSON字符串
json.dump(data, f) # 写入JSON文件
json_str = '{"name": "Bob"}'
data = json.loads(json_str) # 反序列化
JSON支持更多语言,可以作为通用数据格式,但只能序列化基本类型。
Turtle图形
Turtle可以用来绘制简单的图形。
import turtle
turtle.forward(100) # 向前移动100单位长度
turtle.right(90) # 向右旋转90度
turtle.width(5) # 设置画笔宽度
turtle.pencolor('red')
turtle.begin_fill() # 开始填充图形
# 绘制形状
turtle.end_fill() # 填充完成
turtle.done() # 保持窗口打开
至此
已学习的主要内容:
- 基础数据类型:字符串、列表、元组、字典、集合
- 函数:定义、参数、递归、高阶函数
- 面向对象编程:类、对象、继承、多态
- 错误处理和调试
- 模块、包管理
- 文件和IO
- 序列化:pickle、JSON
进阶内容:
- 网络编程:Socket、WSGI、Web框架
- GUI编程:Tkinter、PyQt等
- 科学计算和数据分析:NumPy、Pandas、Matplotlib等
- Web爬虫:requests、BeautifulSoup、Scrapy等
- 图像处理:OpenCV、Pillow等
- 神经网络:TensorFlow、PyTorch等
- 游戏开发:PyGame等
- 系统管理:进程、线程、正则表达式等



